Реалистичные забавные выражения лица! Facebook модернизирует свою технологию аватаров VR Modular Codec Avatars
Исследовательская организация Facebook, Facebook Reality Labs (FRL), возглавляет исследования и разработку виртуальных аватаров и стремится достичь эффектов, превосходящих «эффект сверхъестественной долины». Новое исследование FRL исследует новую поддержку выражения лица, позволяющую друзьям точно увидеть ваше смешное лицо в виртуальной реальности.
Документ по теме: Выразительное телеприсутствие с помощью аватаров модульных кодеков
Сегодня большинство аватаров в VR выполнены в мультяшном, а не в гуманоидном стиле. В основном это делается для того, чтобы избежать проблемы «Страшной долины»: когда степень персонификации достигает определенного уровня, человеческая реакция внезапно становится отрицательной.
1. Предыдущий проект: Codec Avatars
Проект «Аватар кодека» компании Facebook Reality Labs направлен на объединение машинного обучения и компьютерного зрения для создания сверхреалистичного воспроизведения пользователей, преодолевая, таким образом, эффект зловещей долины. Исследователи в основном обучают систему распознавать человеческое лицо, а затем воспроизводят выражение лица на основе входных данных с камеры, закрепленной на голове. Этот проект уже показал очень впечатляющие результаты.

Точное воспроизведение типичной позы лица уже является огромной проблемой, и тогда вам придется иметь дело с бесчисленным множеством крайних ситуаций, и любая из них может вывести из строя всю систему и вернуть виртуальный аватар к эффекту сверхъестественной долины.
Исследователи Facebook отметили, что самая большая проблема заключается в том, что «нецелесообразно разрабатывать единообразный образец всех потенциальных (мимических) выражений», потому что существует так много разных способов изменения лица. В конечном итоге это означает, что в выборочных данных системы будет пробел, так что она будет сбита с толку, когда увидит новое лицо.
2. Проект-преемник: Modular Codec Avatars
Исследователи Ханг Чу, Шугао Ма, Фернандо Де ла Торре, Санджа Фидлер и Ясер Шейх из Университета Торонто, Vector Institute и Facebook Reality Labs в заголовке «Выразительное телеприсутствие с помощью аватаров модульных кодеков» Решение предлагается в его недавно опубликованной статье.
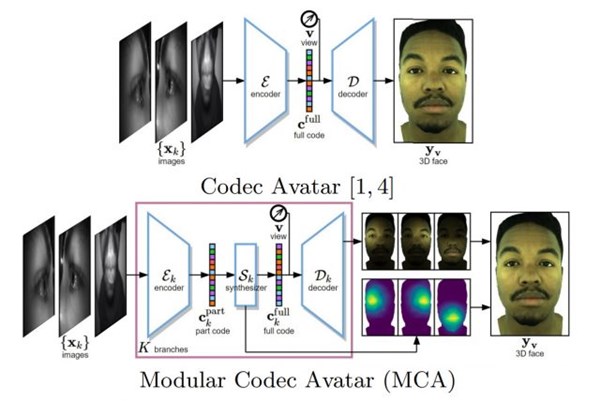
Исходная система аватара кодека сопоставляет все выражения лица в наборе данных с видимым вводом, в то время как система аватара модульного кодека разделяет задачи в соответствии с отдельными чертами лица, такими как глаза и рот, чтобы можно было объединить несколько Лучшее сочетание различных поз для создания наиболее точной осанки лица.
В Modular Codec Avatars модульный кодировщик сначала извлекает информацию из каждой камеры, установленной на голове. Далее идет модульный синтезатор, который оценивает полное выражение лица и его вес смешивания на основе информации, извлеченной из той же модульной ветви. Наконец, объедините несколько предполагаемых трехмерных лиц из разных модулей и сформируйте окончательный результат лица.
Цель команды - оптимизировать диапазон выражений, которые можно точно представить, не предоставляя системе дополнительные данные для обучения. Можно сказать, что цель системы Modular Codec Avatar - лучше понять, как должно выглядеть лицо, в то время как исходная система Codec Avatar больше полагается на прямое сравнение.
3. Проблема гримасы
Одним из основных преимуществ описанного метода является то, что он улучшает способность системы воспроизводить новые выражения лица, которые не обучены для связанных выражений, например, когда люди намеренно манипулируют своими лицами интересными способами. В статье исследователи отметили это особое преимущество: «Создание интересных выражений лица является частью социальной деятельности. Благодаря большей выразительности модель Modular Codec Avatar может естественным образом и лучше облегчить эту задачу».
В ходе теста они случайным образом меняли черты лица в совершенно разных позах, таких как левый глаз {поза A}, правый глаз {поза B}, рот {поза C}, и наблюдали, может ли система воспроизводить реалистичные черты лица при различных входных параметрах. результат.
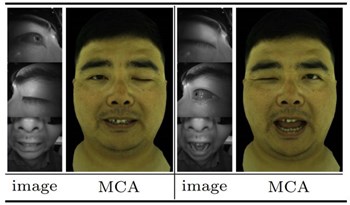
Исследователи заявили: «(На картинке выше) видно, что аватары модульных кодеков по-прежнему могут воспроизводить естественные и гибкие выражения, даже если они никогда полностью не встречались в обучающем наборе».
Мы с нетерпением ждем возможности воспроизводить всевозможные забавные выражения, являясь главной задачей системы.
4. Увеличенные глаза
Помимо забавных выражений лица, исследователи обнаружили, что система Modular Codec Avatar также может устранить естественную разницу в положении глаз при ношении гарнитуры, тем самым улучшая реализм лица.
В реальном телеприсутствии VR мы наблюдаем, что пользователи часто не открывают глаза полностью естественным образом. Это может быть связано с чрезмерным давлением мышц при ношении гарнитуры и отображением источников света возле глаз. Поэтому мы представляем ручку управления увеличением глаза, чтобы решить эту проблему.
Это позволяет системе тонко модифицировать глаза, чтобы приблизить их к фактическому лицу пользователя, когда он не носит гарнитуру.

Концепция реконструкции человеческих лиц путем объединения характеристик различных фрагментов выборочных данных не нова, но исследователи заявили: «Наш модуль не использует линейные или мелкие элементы на трехмерных сетках, как в предыдущем методе, но Это выполняется в скрытом пространстве, изученном глубокой нейронной сетью. Это позволяет улавливать сложные нелинейные эффекты и создавать лицевые анимации с новым уровнем реализма ».
Этот метод также должен сделать изображение аватара более практичным. Для достижения отличных результатов Codec Avatars требуемые данные обучения требуют от вас захвата большого количества сложных поз лиц реальных пользователей. Модульные аватары кодеков позволяют добиться большей выразительности с меньшим количеством обучающих данных и добиться аналогичных эффектов.
Чтобы помочь пользователям, у которых нет машин для сканирования лиц, добиться таких точных выражений лица, нам все равно нужно подождать определенное время. Но с непрерывным развитием технологий в один прекрасный день пользователи смогут быстро и легко снимать собственные модели лиц с помощью приложений для смартфонов, загружать их и использовать в качестве основы для виртуальных аватаров, которые пересекают эффект зловещей долины.
© 2020 www.ourvrworld.com