Realistic facial funny expressions! Facebook upgrades its VR avatar technology Modular Codec Avatars
Facebook's research organization, Facebook Reality Labs (FRL), has been leading the research and development of virtual avatars and is committed to achieving effects that exceed the "uncanny valley effect". A new study by FRL explores novel facial expression support, allowing friends to accurately see your funny face in virtual reality.
Related paper: Expressive Telepresence via Modular Codec Avatars
Today, most avatars in VR are cartoon style rather than humanoid style. This is mainly to avoid the "Uncanny Valley" problem: when the degree of personification reaches a certain level, the human response will suddenly become negative.
1. Previous project: Codec Avatars
The "Codec Avatar" project of Facebook Reality Labs aims to combine machine learning and computer vision to create a super-realistic reproduction of users, thus transcending the uncanny valley effect. Researchers mainly train the system to understand a human face, and then reproduce the expression based on the input from the head-mounted display camera. This project has already demonstrated very impressive results.

Accurately reproducing the typical facial posture is already a huge challenge, and then you have to deal with countless edge situations, and any one of them may crash the entire system and bring the virtual avatar back to the uncanny valley effect.
Facebook researchers pointed out that the biggest challenge is "it is impractical to develop a uniform sample of all potential (facial) expressions" because there are so many different ways of changing faces. Ultimately, this means that there will be a gap in the sample data of the system so that it will be confused when it sees a new face.
2. Successor project: Modular Codec Avatars
Researchers Hang Chu, Shugao Ma, Fernando De la Torre, Sanja Fidler and Yaser Sheikh from the University of Toronto, Vector Institute and Facebook Reality Labs in the title "Expressive Telepresence via Modular Codec Avatars" A solution is proposed in his newly published paper.
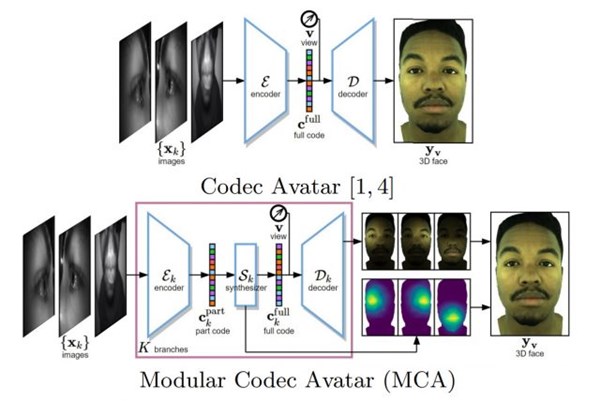
The original Codec Avatar system matches the entire facial expressions in the dataset with the input seen, while the Modular Codec Avatar system divides tasks according to individual facial features such as eyes and mouth, so that it can merge several The best match of different postures to synthesize the most accurate facial posture.
In Modular Codec Avatars, the modular encoder first extracts information within each head-mounted camera view. Next is a modular synthesizer, which estimates a complete facial expression and its blend weight based on the information extracted from the same modular branch. Finally, aggregate multiple estimated three-dimensional faces from different modules and form the final face output.
The team's goal is to optimize the range of expressions, which can be accurately presented without providing more training data to the system. It can be said that the purpose of the Modular Codec Avatar system is to better infer what a face should look like, while the original Codec Avatar system relies more on direct comparison.
3. The challenge of making faces
One of the main advantages of the described method is that it improves the system's ability to reproduce new facial expressions, which is not trained for related expressions, such as when people deliberately manipulate their faces in interesting ways. The researchers pointed out this special advantage in the paper: "Making interesting expressions is part of social activities. Because of the stronger expressiveness, the Modular Codec Avatar model can naturally and better facilitate this task."
In the test, they randomly changed facial features in completely different poses, such as left eye {pose A}, right eye {pose B}, mouth {pose C}, and observed whether the system can produce lifelike features given different feature inputs result.
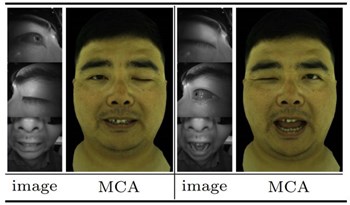
The researchers said: "(In the picture above) it can be seen that Modular Codec Avatars can still produce natural and flexible expressions even if they have never been seen completely in the training set."
As the ultimate challenge of the system, we look forward to it being able to reproduce all kinds of funny expressions.
4. Enlarged eyes
In addition to funny facial expressions, the researchers found that the Modular Codec Avatar system can also eliminate the inherent difference in eye posture when wearing a headset, thereby improving facial realism.
In actual VR telepresence, we observe that users often do not open their eyes completely naturally. This may be due to excessive muscle pressure when wearing the headset and the display of light sources near the eyes. Therefore, we introduce an eye magnification control knob to solve this problem.
This allows the system to subtly modify the eyes to bring them closer to the actual face of the user when not wearing the headset.

The concept of reconstructing human faces by fusing the features of different sample data fragments is not new, but the researchers said, "Our module does not use linear or shallow features on 3D grids like the previous method, but It is carried out in the latent space learned by the deep neural network. This makes it possible to capture complex nonlinear effects and make facial animations with a new level of realism."
This method is also to make this avatar representation more practical. For Codec Avatars to achieve great results, the training data required requires you to capture a large number of complex facial poses of real users. Modular Codec Avatars can achieve higher expressiveness with less training data and achieve similar effects.
To support users who do not have face scanning machines to achieve such accurate facial expressions, we still need to wait a certain amount of time. But with the continuous advancement of technology, one day users can quickly and easily capture their own facial models through smartphone applications, upload them, and use them as the basis for virtual avatars that cross the uncanny valley effect.
© 2020 www.ourvrworld.com